 豆瓣书籍数据(基于R)"/>
豆瓣书籍数据(基于R)"/>
爬取豆瓣书籍数据(基于R)
爬取豆瓣书籍数据(基于R)
- 爬取豆瓣书籍数据
- 了解网页结构
- 自动收集单个网页数据
- 自动收集多个网页数据
- 字符串切割,以提取需要的信息
爬取豆瓣书籍数据
网络爬虫,就是从网页中获取需要的信息,提取相应的数据。
可以利用R语言爬虫获取网页数据信息,便于统计分析。
常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以利用RSslenium包或者Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。
本文便以爬取豆瓣电影数据为例,来描述网络爬虫过程。
爬取网址如下:
=0
<本文是学习《R语言统计分析与机器学习》后的学习笔记>
了解网页结构
所需要的数据概况:
从网页中大概能发现,该网页含有书籍名称,书籍评分,书籍主题,出版时间,价格,作者名字,译者名字等数据信息。
再进入网页源代码界面找规律
可以发现有十分一致的规律:
书籍名称:
<div class="pl2"><a href="/" onclick="moreurl(this,{i:'0'})" title="红楼梦"> 红楼梦
</a>
作者/译者/出版社/出版时间/价格:
</div>
<p class="pl">[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元</p>
评分信息:
<div class="star clearfix"><span class="allstar50"></span><span class="rating_nums">9.6</span><span class="pl">(278287人评价)</span>
</div>
下面便利用发现的规律,利用R进行数据爬取。
自动收集单个网页数据
- 导入需要的包 ,导入需要的包;
library(dplyr)
library(rvest)
library(stringr)
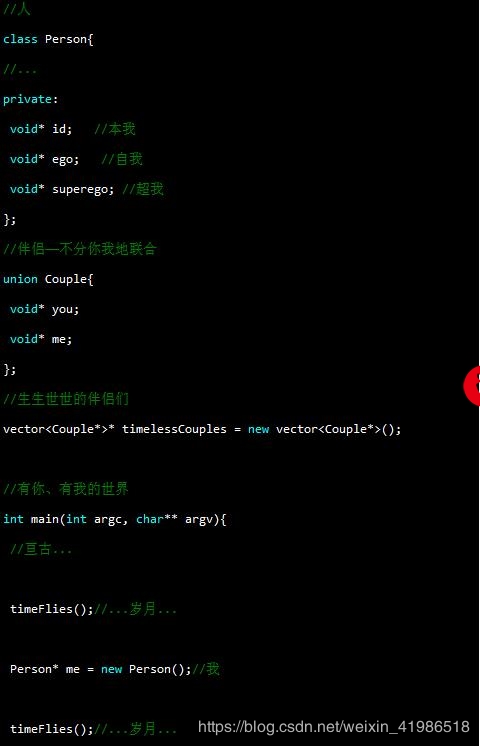
- 读取网页,并进行数据提取 ,读取网页,程序如下:
alldata250<-data.frame()u1<-paste("=",0,sep = "", collapse = NULL)#字符串拼接## 读取网页top250book<-read_html(u1)## 评分水平mark<-top250book %>% html_nodes("span.rating_nums") %>% html_text()#作品名称name<-top250book %>% html_nodes("div.pl2 a") %>% html_text()%>%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")head(name)#作者/出版社/日期/年份/价格place <-top250book%>% html_nodes("p.pl") %>% html_text()work<-data.frame(name,mark,place)#创建数据框#下面将place中的字符串拆开,便于分析alldata250<-rbind(alldata250,work)
}
运行结果
此时,我们成功爬取了第一页的数据,那么如何利用程序自动爬取其他页面的数据呢?
我们可以观察网址的规律。
- 第一页:=0
- 第二页:=25
- 第三页:=50
我们可以发现加粗部分,存在以25递增的关系,其他的保持不变。故我们可以考虑利用循环的方式进行爬取。
自动收集多个网页数据
字符串的拼接,网址是一串较为复杂的字符串,但本例之中,大部分内容不改变,改变的仅仅是数字,故我们可以考虑利用字符串拼接的方式,得到不同页面的网址链接。
字符串拼接函数:
paste(......, sep = " ", collapse = NULL)
其中……表示一个或多个可以被转化为字符型的对象;
参数sep表示分隔符,默认为空格;
参数collapse可选,如果不指定值,那么函数paste的返回值是自变量之间通过sep指定的分隔符连接后得到的一个字符型向量; 如果为其指定了特定的值,那么自变量连接后的字符型向量会再被连接成一个字符串,之间通过collapse的值分隔。下面用具体的例子说明各参数的作用
本例中,对网页进行拼接可得到:
> i=9
> u1<-paste("=",25*i,sep = "", collapse = NULL)#字符串拼接
> print(u1)
[1] "=225"
其中i是从0开始增加,每个i对应一个网页页面,故可由i循环,以达到反复爬取网页数据的功能。
程序如下:
library(dplyr)
library(rvest)
library(stringr)
alldata250<-data.frame()
for(i in 0:9){u1<-paste("=",25*i,sep = "", collapse = NULL)#字符串拼接## 读取网页top250book<-read_html(u1)## 评分水平mark<-top250book %>% html_nodes("span.rating_nums") %>% html_text()#作品名称name<-top250book %>% html_nodes("div.pl2 a") %>% html_text()%>%str_trim()%>%str_replace_all("\n|","")%>%str_replace_all(" ","")head(name)#作者/出版社/日期/年份/价格place <-top250book%>% html_nodes("p.pl") %>% html_text()work<-data.frame(name,mark,place)#创建数据框#下面将place中的字符串拆开,便于分析alldata250<-rbind(alldata250,work)
}
运行结果如下:
本例探究的是爬取网页中的文本数据,注意得从网页源代码找规律,同时注意对文本数据字符串的处理方法。
字符串切割,以提取需要的信息
**但由上面结果可发现,place一列,是多个信息数据以/为间隔组合在一起的,故我们设法将其拆分,以获得更准确的数据,便于统计分析。
可发现不同书籍对应的place部分数据个数并不相同:
其中“/”的数量就有2,3,4,5等四种情况,"/"数量不同,意味着数据个数也不同。比如,有些书籍并没有作者信息,有些书籍没有译者信息,有些书籍有两种价格。
尝试根据"/“的数量作为标签,对于不同的”/"数量的信息进行分别处理赋值。
#再对place中进行切分work<-alldata250label<-str_count(work$place,"/")#统计place中/符号的个数,因为有n个“/”意味着有n+1个数据work$label<-label#将label添加进数据框work2<-work[label==2,]#筛选有两个/的部分work3<-work[label==3,]#筛选有三个/的部分work4<-work[label>=4,]#筛选有四个以上/的部分
再利用strsplit()函数,根据/为间隔符,将其拆分开,使用格式如下:
#含有两个/的部分palce2<-as.character(work2$place)#将其转化为字符格式palce2<-strsplit(palce2,split="/")#根据/为间隔符,将其拆分
#含有三个/的部分palce3<-as.character(work3$place)#将其转化为字符格式palce3<-strsplit(palce3,split="/")#根据/为间隔符,将其拆分
#含有四个/的部分palce4<-as.character(work4$place)#将其转化为字符格式palce4<-strsplit(palce4,split="/")#根据/为间隔符,将其拆分
下面对各种情况进行观察,便于寻找规律正确赋值。
观察含有两个/的结构
> head(palce2)
[[1]]
[1] "中国基督教协会 " " 中国基督教协会 " " 1996"
[[2]]
[1] "中华书局 " " 2006-12 " " 9.80元"
可发现数量仅有2个,且格式不统一,故暂不作处理。
观察含有三个/的结构
> head(palce3)
[[1]]
[1] "[清] 曹雪芹 著 "" 人民文学出版社 " " 1996-12 " " 59.70元"
[[2]]
[1] "余华 " " 作家出版社 " " 2012-8-1 " " 20.00元"
[[3]]
[1] "刘慈欣 " " 重庆出版社 " " 2012-1-1 " " 168.00元"
[[4]]
[1] "[明] 罗贯中 " " 人民文学出版社 " " 1998-05 " " 39.50元"
[[5]]
[1] "林奕含 " " 北京联合出版公司 " " 2018-1 " " 45.00元"
[[6]]
[1] "金庸 " " 生活.读书.新知三联书店 " " 1994-5 " " 96.0"
可发现每层第一个是作者信息,第二个是出版社信息,第三个是出版时间,第四个是价格。
观察含有四个以上/的结构
[[1]]
[1] "[哥伦比亚] 加西亚·马尔克斯 " " 范晔 " " 南海出版公司 " " 2011-6 "
[5] " 39.50元" [[2]]
[1] "[英] 乔治·奥威尔 " " 刘绍铭 " " 北京十月文艺出版社 " " 2010-4-1 " " 28.00" [[3]]
[1] "[美国] 玛格丽特·米切尔 " " 李美华 " " 译林出版社 " " 2000-9 " " 40.00元" [[4]]
[1] "[日] 东野圭吾 " " 刘姿君 " " 南海出版公司 " " 2013-1-1 " " 39.50元" [[5]]
[1] "[英] 阿·柯南道尔 " " 丁钟华 等 " " 群众出版社 " " 1981-8 " " 53.00元" "68.00元" [[6]]
[1] "[英] 乔治·奥威尔 " " 荣如德 " " 上海译文出版社 " " 2007-3 " " 10.00元"
可发现每层第一个是作者信息,第二个是译者信息,第三个是出版社信息,第四个是出版时间,第五个是价格,如果有第六个,那就是有两种价格,这里暂不考虑。
可以利用循环语句,对含不同”/“数量的信息分别进行提取。 程序如下:
含有两个"/"时:
#字符串中有2个/的writer<-c()public<-c()date<-c()price<-c()translate<-c()for(i in 1:length(palce2)){#writer<-c(writer,palce2[[i]][1])#每层中第一个为作家名称public<-c(public,palce2[[i]][1])#每层中第二个为出版社信息date<-c(date,palce2[[i]][2])#每层第三个是出版日期price<-c(price,palce2[[i]][3])#每层第四个是价格信息}other2<-data.frame(public,date,price)a<-length(date)other2$translate<-rep("NULL",a)#这部分没有翻译人员名称,所以填充为NULLother2$writer<-rep("NULL",a)#这部分没有翻译人员名称,所以填充为NULL
含有三个"/"时:
#字符串中有3个/的writer<-c()public<-c()date<-c()price<-c()translate<-c()for(i in 1:length(palce3)){writer<-c(writer,palce3[[i]][1])#每层中第一个为作家名称public<-c(public,palce3[[i]][2])#每层中第二个为出版社信息date<-c(date,palce3[[i]][3])#每层第三个是出版日期price<-c(price,palce3[[i]][4])#每层第四个是价格信息}other3<-data.frame(writer,public,date,price)a<-length(date)other3$translate<-rep("NULL",a)#这部分没有翻译人员名称,所以填充为NULL含有四个"/"时:
#字符串中有4个/的writer<-c()public<-c()date<-c()price<-c()translate<-c()for(i in 1:length(palce4)){writer<-c(writer,palce4[[i]][1])#每层第一个是作家名称public<-c(public,palce4[[i]][3])#每层第三个是出版社信息date<-c(date,palce4[[i]][4])#每层第四个是出版日期price<-c(price,palce4[[i]][5])#每层第5个是价格信息translate<-c(translate,palce4[[i]][2])#每层第二个是翻译人员名字}other4<-data.frame(writer,public,date,price,translate)
再将得到的各情况下的数据进行按行合并整理:
other<-rbind(other2,other3,other4)#按行合并
尤其注意此时由于分类别操作已经改变了顺序,故得按照类别顺序进行合并,程序如下:
work<-rbind(work2,work3,work4)#按行合并
#再将work和other数据框按列合并,即可得到完整的数据
TOPdata<-cbind(work,other)#按列合并
结果如下:
由此即可划分开字符串了,便于对其进行进一步的分析。
更多推荐
爬取豆瓣书籍数据(基于R)











发布评论