 正文解析器实际上是如何表达的?"/>
正文解析器实际上是如何表达的?"/>
正文解析器实际上是如何表达的?
[好,所以我正在浏览我的旧节点代码,该代码是我在遵循一些教程时编写的。
我很难弄清Body Parser的确切功能。我也在使用ejs package
所以,我的基本直觉告诉我,正文解析器用于在节点和html模板之间传输数据,而ejs包用于将javascript嵌入HTML模板。
有人可以确认我的想法是否正确吗?由于某种原因,它们的文档似乎太先进了,我无法理解。另外,是否有人还可以确认**npm request**的功能是进行API调用?
回答如下:让我们尽量保持最低的技术水平。
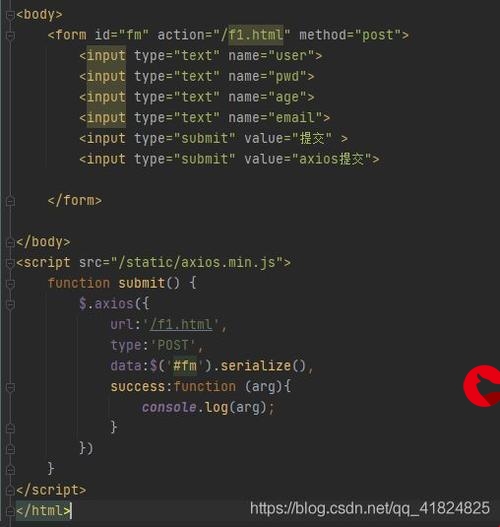
假设您正在将HTML表单数据发送到node-js服务器,即您向服务器发出了请求。服务器文件将在请求对象下接收您的请求。现在按逻辑,如果您在服务器文件中控制台记录此请求对象,则应该在其中的某些位置看到表单数据,然后可以将其提取出来,但是哇!你实际上不是!
所以,我们的数据在哪里?如果它不仅出现在我的请求中,我们将如何提取它。
对此的简单解释是http发送的表单数据是零散的,目的是在到达目的地时进行组装。那么您将如何提取数据。
此处描述了一种实际方法:How bodyParser() works – Adam Zerner – Medium
但是,为什么要每次手动手动分析数据并将其组装起来,却会费心费力。使用一种叫做“ body-parser”的东西可以为您做到这一点。
body-parser解析您的请求并将其转换为一种格式,您可以从中轻松提取您可能需要的相关信息。
例如,假设您在前端有一个注册表格。您正在填充它,并请求服务器将详细信息保存在某处。
如果使用body-parser,从请求中提取用户名和密码将变得很简单,如下所示。
……………………………………………………
var loginDetails = {
username : request.body.username,
password : request.body.password
};
……………………………………………………
因此,基本上,body-parser解析您的传入请求,组装包含您的表单数据的块,然后为您创建此body对象,并用您的表单数据填充它。
更多推荐
正文解析器实际上是如何表达的?











发布评论