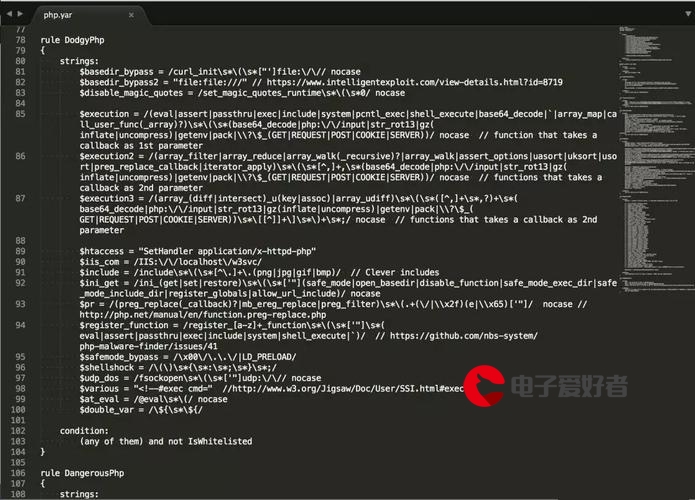
 爬虫程序入门(图片下载)"/>
爬虫程序入门(图片下载)"/>
一、python爬虫程序入门(图片下载)
/?kw=%E6%96%87%E8%B1%AA%E9%87%8E%E7%8A%AC&type=feed#!s-p1
这个url下面的图片具备这样的规律:
<a target="_blank" class="a" href="/blog/?id=728506209">
<img data-rootid="728506209" alt="文豪野犬" data-iid="" src=".thumb.224_0.jpeg" height="329">
<u style="margin-top:-329px;height:327px;" class=""></u>
</a>
——见红色字体
#!/usr/bin/python
#-*- coding: utf-8 -*-
#encoding=utf-8
import urllib
from urllib import request
import os
from bs4 import BeautifulSoupdef getAllImageLink():html = request.urlopen('/?kw=%E6%96%87%E8%B1%AA%E9%87%8E%E7%8A%AC&type=feed#!s-p1').read()#print(len(html))soup = BeautifulSoup(html, "html.parser")#print(soup.prettify())li_request = soup.find_all('a', class_='a')#print (li_request)count = 0for myimg in li_request:link = myimg.find('img').get('src')pic_name = 'F:/image/python/' + str(count) + '.jpg'urllib.request.urlretrieve(link, pic_name)count += 1if __name__ == '__main__':getAllImageLink()更多推荐
一、python爬虫程序入门(图片下载)











发布评论