 决策树学习"/>
决策树学习"/>
sklearn之决策树学习
决策树(Decision Trees):非参数有监督学习,用来分类和回归
决策树(DecisionTrees):非参数有监督学习,用来分类和回归
目标:从数据特征学习得到简单决策,从而创建一个可以预测目标变量的模型
决策树的优点:
(1) 易理解,可视化方便
(2) 数据准备少,注意:此模块不支持缺失值
(3) 计算复杂度与模型数据点呈对数关系
(4) 数值型和类别型数据均可处理
(5) 可以解决多输出问题
(6) 采用白箱模型
(7) 可通过数据测试验证模型可靠性
(8) 假设与真实模型有冲突时表现较好
决策树的缺点:
(1) 易过拟合,可通过剪枝、设置叶子结点最小样本数或设置决策树最大深度来避免
(2) 稳定性差,数据的微小变化可能引起决策树很大的改变,可通过集成的决策树缓和
(3) 决策树学习优化问题为一个NP完全问题,因此实际决策树算法为基于启发式的算法(例如贪心算法),不能保证取得全局最优决策树,可采用随机森林解决
(4) 概念不易表达,例如XOR,奇偶性和多路复用器问题
(5) 如果某类别数量多占主导地位,决策树易学习到有偏树,因此建议优先平衡数据集各类别数量
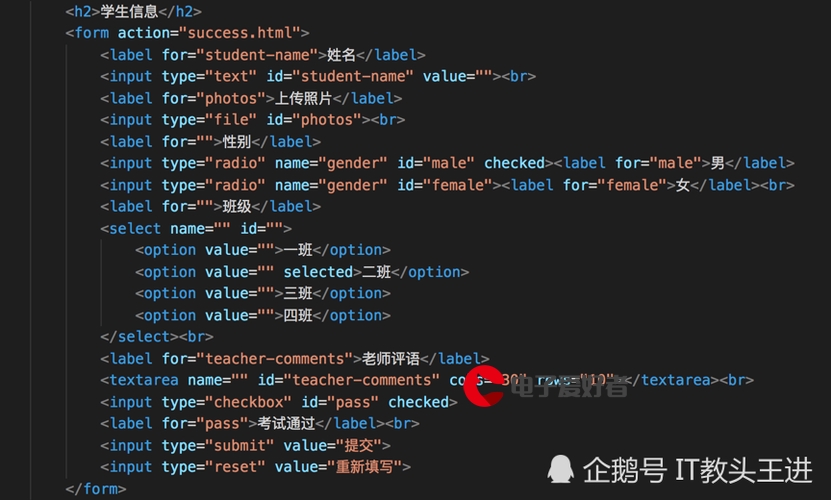
1.分类(DecisionTreeClassifier)
(1)输入
数组X:样本数组(稀疏或紧密),大小为[n_samples,n_features]
向量y:样本实际值,大小[n_samples]
(2)拟合
(3)预测样本类别
(4)预测样本类别可能性,为一个叶子结点上相同类别样本所占百分数
(5)可预测二元分类,标签值默认为[1,-1],或k元分类,标签值默认为[0,1,…k-1]
(6)训练完成可用export_graphviz导出决策树可视化框架
2.回归(DecisionTreeRegressor)
(1)输入:除了输出y用浮点数代替之外,其余与分类相同
(2)预测:
3.多输出问题
(1)有监督学习问题,输出值Y为2D数组而不是向量,[n_samples,n_outputs]
(2)若各输出之间没有关联性,可将问题化为n个独立模型,分别预测输出;
若输出之前具有关联性,通常建立单个模型同时预测多个输出,可以减少训练时间并提高模型精确度
(3)与传统决策树有以下不同:
叶子结点储存多个输出值
用不同标准计算n个输出值的平均减少量
(4)拟合及预测同单输出决策树
4.复杂度
算法复杂度:O(nsamples2nfeatureslog(nsamples))
Sklearn处理复杂度:O(nsamplesnfeatureslog(nsamples))
梯度提升算法中默认打开,其余算法则关闭(因为训练越深,训练时间越慢)
5.建议
(1)样本数与特征数之比的重要性,高维空间少样本极易引起过拟合
(2)可采用PCA,ICA或特征选择进行降维
(3)可设置树最大深度为3,并可视化树获得直观感受并对其进行改进
(4)可设置树最大深度防止过拟合(max_depth)
(5)可设置叶子结点最小样本数(min_samples_leaf or min_samples_split)
初始值可设置为5
min_samples_leaf:叶子结点中最小样本数
min_samples_split:叶子结点最小样本分割数(文献中更普遍)
(6)平衡数据集,可通过给每类样本设置相同权重(samlple_weight)
(7)以权重为基础的预剪枝,min_weight_fraction_leaf可减少数据集偏差
(8)所有决策树本质都为np.float32数组,若训练数据与此形式不同,则数据集被复制
(9)若输入矩阵X为稀疏阵,可在拟合前调用csc_matrix,预测前调用csr_matrix对其转化
6.决策树算法评价指标
(1)ID3:信息增益
(2)C4.5:信息增益率
(3)C5.0:与4.5相比,使用更小内存和决策规则,结果更精确
(4)CART:gini指数
更多推荐
sklearn之决策树学习











发布评论