 验证码 1 豆瓣"/>
验证码 1 豆瓣"/>
Python模拟登陆 —— 征服验证码 1 豆瓣
captcha是Completely Automated Public Turing Test to Tell Computers and Humans Apart ,全自动区分计算机和人类的图灵测试)的简称。
登陆失败若干次之后,豆瓣登录页面才会出现验证码。所以为了确保py文件运行正确,要先故意输错几次,出现验证码框之后,再运行。:)
登录界面使用Python3.6。
from urllib.request import urlretrieve
import requests
from bs4 import BeautifulSoup
from os import remove
try:import cookielib
except:import http.cookiejar as cookielib
try:from PIL import Image
except:passurl = ''datas = {'source': 'index_nav','remember': 'on'}headers = {'Referer': '/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'' (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8'}# 尝试使用cookie信息
session = requests.session()
session.cookies = cookielib.LWPCookieJar(filename='cookies')
try:session.cookies.load(ignore_discard=True)
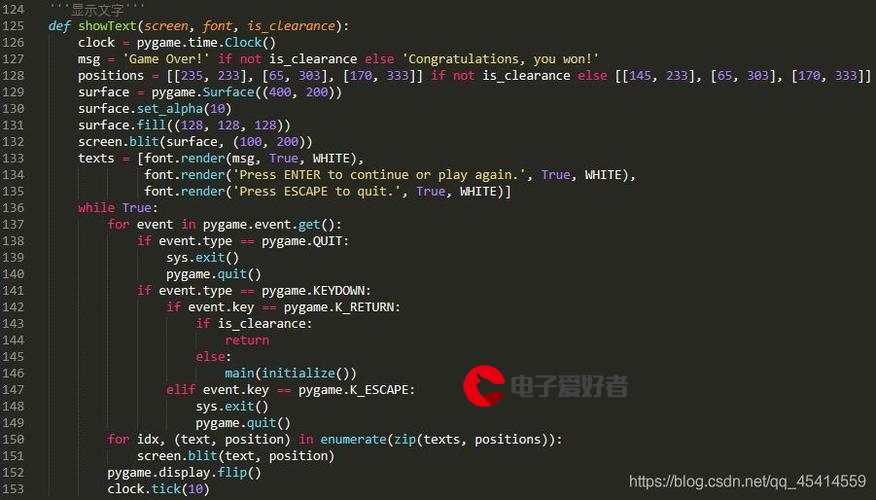
except:print("Cookies未能加载")#cookies加载不成功,则输入账号密码信息datas['form_email'] = input('Please input your account:')datas['form_password'] = input('Please input your password:')def get_captcha():'''获取验证码及其ID'''r = requests.post(url, data=datas, headers=headers)page = r.textsoup = BeautifulSoup(page, "html.parser")# 利用bs4获得验证码图片地址img_src = soup.find('img', {'id': 'captcha_image'}).get('src')urlretrieve(img_src, 'captcha.jpg')try:im = Image.open('captcha.jpg')im.show()im.close()except:print('到本地目录打开captcha.jpg获取验证码')finally:captcha = input('please input the captcha:')remove('captcha.jpg')captcha_id = soup.find('input', {'type': 'hidden', 'name': 'captcha-id'}).get('value')return captcha, captcha_iddef isLogin():'''通过查看用户个人账户信息来判断是否已经登录'''url = "/"login_code = session.get(url, headers=headers,allow_redirects=False).status_codeif login_code == 200:return Trueelse:return Falsedef login():captcha, captcha_id = get_captcha()# 增加表数据datas['captcha-solution'] = captchadatas['captcha-id'] = captcha_idlogin_page = session.post(url, data=datas, headers=headers)page = login_page.textsoup = BeautifulSoup(page, "html.parser")result = soup.findAll('div', attrs={'class': 'title'})#进入豆瓣登陆后页面,打印热门内容for item in result:print(item.find('a').get_text())# 保存 cookies 到文件,# 下次可以使用 cookie 直接登录,不需要输入账号和密码session.cookies.save()if __name__ == '__main__':if isLogin():print('Login successfully')else:login()
将标题抓取下来了!
运行结果更多推荐
Python模拟登陆 —— 征服验证码 1 豆瓣











发布评论