 分布式Hadoop集群搭建过程"/>
分布式Hadoop集群搭建过程"/>
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)
另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!
第一部分 Hadoop 2.2 下载
Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:.2.0/
如下图所示,下载红色标记部分即可。如果要自行编译则下载src.tar.gz.
第二部分 集群环境搭建
1、这里我们搭建一个由三台机器组成的集群:
192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit
192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit
192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit
1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)
1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)
1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。(切换到root账户,修改/etc/sudoers文件,增加:hduser ALL=(ALL) ALL )
2、修改/etc/hosts 文件,增加三台机器的ip和hostname的映射关系
192.168.0.1 cloud001
192.168.0.2 cloud002
192.168.0.3 cloud003
3、打通cloud001到cloud002、cloud003的SSH无密码登陆
3.1 安装ssh
一般系统是默认安装了ssh命令的。如果没有,或者版本比较老,则可以重新安装:
sodu apt-get install ssh
3.2设置local无密码登陆
安装完成后会在~目录(当前用户主目录,即这里的/home/hduser)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件)。如果没有这个文件,自己新建即可(mkdir .ssh)。
具体步骤如下:
1、 进入.ssh文件夹
2、 ssh-keygen -t rsa 之后一路回 车(产生秘钥)
3、 把id_rsa.pub 追加到授权的 key 里面去(cat id_rsa.pub >> authorized_keys)
4、 重启 SSH 服 务命令使其生效 :service sshd restart(这里RedHat下为sshdUbuntu下为ssh)
此时已经可以进行ssh localhost的无密码登陆
【注意】:以上操作在每台机器上面都要进行。
3.3设置远程无密码登陆
这里只有cloud001是master,如果有多个namenode,或者rm的话则需要打通所有master都其他剩余节点的免密码登陆。(将001的authorized_keys追加到002和003的authorized_keys)
进入001的.ssh目录
scp authorized_keys hduser@cloud002:~/.ssh/ authorized_keys_from_cloud001
进入002的.ssh目录
cat authorized_keys_from_cloud001>> authorized_keys
至此,可以在001上面sshhduser@cloud002进行无密码登陆了。003的操作相同。
4、安装jdk(建议每台机器的JAVA_HOME路径信息相同)
注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install)
4.1、下载jkd( .html)
4.1.1 对于32位的系统可以下载以下两个Linux x86版本(uname -a 查看系统版本)
4.1.2 64位系统下载Linux x64版本(即x64.rpm和x64.tar.gz)
4.2、安装jdk(这里以.tar.gz版本,32位系统为例)
安装方法参考.html
4.2.1 选择要安装java的位置,如/usr/目录下,新建文件夹java(mkdirjava)
4.2.2 将文件jdk-7u40-linux-i586.tar.gz移动到/usr/java
4.2.3 解压:tar -zxvf jdk-7u40-linux-i586.tar.gz
4.2.4 删除jdk-7u40-linux-i586.tar.gz(为了节省空间)
至此,jkd安装完毕,下面配置环境变量
4.3、打开/etc/profile(vim /etc/profile)
在最后面添加如下内容:
JAVA_HOME=/usr/java/jdk1.7.0_40(这里的版本号1.7.40要根据具体下载情况修改)
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOMECLASSPATH PATH
4.4、source /etc/profile
4.5、验证是否安装成功:java–version
【注意】每台机器执行相同操作,最后将java安装在相同路径下(不是必须的,但这样会使后面的配置方便很多)
5、关闭每台机器的防火墙
RedHat:
/etc/init.d/iptables stop 关闭防火墙。
chkconfig iptables off 关闭开机启动。
Ubuntu:
ufw disable (重启生效)
更多详情见请继续阅读下一页的精彩内容: .htm
相关阅读:
Ubuntu 13.04上搭建Hadoop环境 .htm
Ubuntu 12.10 +Hadoop 1.2.1版本集群配置 .htm
Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) .htm
Ubuntu下Hadoop环境的配置 .htm
单机版搭建Hadoop环境图文教程详解 .htm
搭建Hadoop环境(在Winodws环境下用虚拟机虚拟两个Ubuntu系统进行搭建) .htm
第三部分 Hadoop 2.2安装过程
由于hadoop集群中每个机器上面的配置基本相同,所以我们先在namenode上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。但需要注意的是集群中64位系统和32位系统的问题。
1、 解压文件
将第一部分中下载的hadoop-2.2.tar.gz解压到/home/hduser路径下(或者将在64位机器上编译的结果存放在此路径下)。然后为了节省空间,可删除此压缩文件,或将其存放于其他地方进行备份。
注意:每台机器的安装路径要相同!!
2、 hadoop配置过程
配置之前,需要在cloud001本地文件系统创建以下文件夹:
~/dfs/name
~/dfs/data
~/temp
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件2:yarn-env.sh
修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件3:slaves (这个文件里面保存所有slave节点)
写入以下内容:
cloud002
cloud003
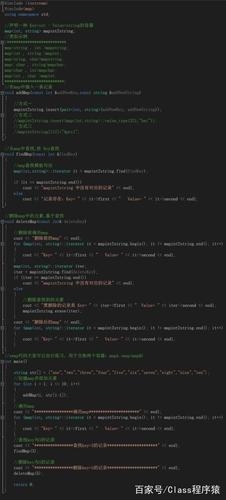
配置文件4:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cloud001:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
配置文件5:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cloud001:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件6:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cloud001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cloud001:19888</value>
</property>
</configuration>
配置文件7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cloud001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> cloud001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> cloud001:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> cloud001:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value> cloud001:8088</value>
</property>
</configuration>
3、复制到其他节点
这里可以写一个shell脚本进行操作(有大量节点时比较方便)
cp2slave.sh
#!/bin/bash
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud002:~/
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud003:~/
注意:由于我们集群里面001是64bit 而002和003是32bit的,所以不能直接复制,而采用单独安装hadoop,复制替换相关配置文件:
Cp2slave2.sh
#!/bin/bash
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud002:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud003:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xml hduser@cloud003:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
4、启动验证
4.1 启动hadoop
进入安装目录: cd ~/hadoop-2.2.0/
格式化namenode:./bin/hdfs namenode –format
启动hdfs: ./sbin/start-dfs.sh
此时在001上面运行的进程有:namenode secondarynamenode
002和003上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在001上面运行的进程有:namenode secondarynamenoderesourcemanager
002和003上面运行的进程有:datanode nodemanaget
查看集群状态:./bin/hdfs dfsadmin –report
查看文件块组成: ./bin/hdfsfsck / -files -blocks
查看HDFS: http://16.187.94.161:50070
查看RM: http:// 16.187.94.161:8088
4.2 运行示例程序:
先在hdfs上创建一个文件夹
./bin/hdfs dfs –mkdir /input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarrandomwriter input
PS:dataNode 无法启动是配置过程中最常见的问题,主要原因是多次format namenode 造成namenode 和datanode的clusterID不一致。建议查看datanode上面的log信息。解决办法:修改每一个datanode上面的CID(位于dfs/data/current/VERSION文件夹中)使两者一致。还有一种解决方法见下面6楼评论! .htm
- 22楼 Rooter 5小时前发表 [回复]
- 博主想问下,为什么http://localhost50070/dfshealth.jsp页面上的Browse the filesystem 不能打开呢?我用单节点和完全分布式的部署都不能打开
- 21楼 zxu618 4天前 09:41发表 [回复]
- 楼主也是64位,你当时如何重新编译的?
- Re: 我是菜鸟要早起 3天前 18:13发表 [回复]
- 回复zxu618:编译方法: .htm
- 20楼 zxu618 2013-11-15 16:40发表 [回复]
- 楼主威武,最近导师让搭个 Hadoop,正愁没有教程呢
- 19楼 a632154894 2013-11-15 13:40发表 [回复]
- 楼主你好,我在启动hdfs: ./sbin/start-dfs.sh的时候出错了。
我把我的配置给你看看
- 18楼 a632154894 2013-11-15 13:34发表 [回复]
- 楼主,你好,我不清楚你那些指令,哪些是在root用户下执行的,哪些是在hduser下执行的!
- Re: 我是菜鸟要早起 3天前 18:12发表 [回复]
- 回复a632154894:可以所有都在hduser 用户下,前提是该用户已经加入到sudoers 文件
- 17楼 淵鴻 2013-11-08 17:44发表 [回复]
- 楼主,为什么我的resourcemanager开起来之后,自动就关了呢,8088端口没有在监听
- Re: 我是菜鸟要早起 2013-11-10 19:04发表 [回复]
- 回复Gameword1:一般这种问题都是集群中结点直接通讯问题导致的。建议你查看namenode上面关于resource manager的log。看看具体错误在哪里
- 16楼 neihaoma 2013-11-08 17:22发表 [回复]
- 楼主啊,,搭建成功了,页面也出来了,但是使用过程中还有好多问题,,求解
- 15楼 neihaoma 2013-11-06 11:57发表 [回复]
- 编译安装顺利完成,十分感谢楼主分享,赞一个
- Re: neihaoma 2013-11-08 15:54发表 [回复]
- 回复u012732153:楼主,有个问题要请教一下,加我
- Re: neihaoma 2013-11-08 15:11发表 [回复]
- 回复u012732153:其他slave节点datanode无法启动,还有一个原因是hosts文件写错了,估计大家不会犯那种错误,反正我是这个原因
- 14楼 snrjmhn 2013-11-06 10:34发表 [回复]
- 请问楼主有没有cygwin上安装hadoop-2.2.0的经验?
我是一新手,在cygwin上安装hadoop-2.2.0后,
用bin/hdfs namenode -format命令时总是提示下边的问题:
▒▒▒▒: ▒Ҳ▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒ org.apache.hadoop.hdfs.server.namenode.NameNode
请指教
- Re: 我是菜鸟要早起 2013-11-10 19:07发表 [回复]
-
抱歉我在cygwin下面没有安装过,不过应该这linux下面没有区别的吧。你的错误信息显示不完全,没看到具体原因
- 13楼 zpc_silenthill 2013-11-05 11:47发表 [回复]
- 新手一枚,按照博主的步骤安装成功了,非常感谢分享。
博主core-site.xml有个笔误<name>fs.defaultFS</name>,估计是<name>fs.default.name</name>。
另外,发现如果<name>fs.default.name</name>的值使用的是机器名的话。在namenode的/etc/hosts中,如果127.0.0.1要放在本机的IP后,否则执行:./bin/hdfs dfsadmin –report,不能看的配置的2个datanode,只能看到本机的。原因不清楚。
- Re: 我是菜鸟要早起 2013-11-05 13:03发表 [回复]
- 回复zpc_silenthill:你遇到的问题2,你试注释到127.0.0.1那一行。
只用IP hostname
- Re: 我是菜鸟要早起 2013-11-05 12:59发表 [回复]
- 回复zpc_silenthill:首先恭喜你成功部署!
name>fs.defaultFS</name>是可以的,我开始部署的时候也注意到这个问题了。老版本的hadoop 上面,参数都是:<name>fs.default.name</name>。应该是2.0以后改成FS这种的(.xml)。如果你部署成功的话,说明参数名是向前兼容的。
- Re: zpc_silenthill 2013-11-05 13:50发表 [回复]
- 回复licongcong_0224:感谢博主细致的回复 赞一个
- 12楼 蜗蜗牛快跑 2013-11-05 11:20发表 [回复]
- 博主有装hbase么?我在装hbase时遇到版本冲突了,求指导呀!
- Re: 我是菜鸟要早起 2013-11-05 12:48发表 [回复]
- 回复superbinbin1:实在抱歉了,最近因为没有用到hbase,直接在hive上面搞一些简单的事情。不过后面是打算把hadoop相关的东西都尝试一下。你可以先琢磨一下,个人觉得hdfs和yarn相关都部署好了,其他的就比较容易了。你提到的版本兼容问题,我猜是因为你的hbase比较老吧。因为hive和hadoop 之间就有个版本的对应问题。要新对新,老对老!
- 11楼 蜗蜗牛快跑 2013-11-05 11:19发表 [回复]
-
后面查了下,发现我也是这个问题!坑爹的,都是复制张贴惹的祸呀!非常感激博主的无私帮助,hadoop成功部署了,哈哈
- Re: 我是菜鸟要早起 2013-11-05 12:45发表 [回复]
- 回复superbinbin1:恭喜恭喜!!网页复制经常出现各种问题。群众的力量是伟大的,哈哈。。欢迎大家共享各种问题!
- 10楼 jackhes02 2013-11-04 10:13发表 [回复]
- 运行任何一条命令都有这条报错信息,请问,怎么处理,谢谢。
[zzhadoop@vm2 hadoop-2.2.0]$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar randomwriter input
13/11/04 10:12:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[zzhadoop@vm2 hadoop]$ hdfs dfsadmin -report
13/11/04 10:04:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- Re: jackhes02 2013-11-04 13:36发表 [回复]
- 回复jackhes02:网上查了一下资料,说是32位hadoop部署在了64为linux上。
hadoop2.2.0遇到64位操作系统平台报错,重新编译hadoop : .htm
- Re: 我是菜鸟要早起 2013-11-04 13:47发表 [回复]
- 回复jackhes02:是的,谢谢提供链接
- Re: 我是菜鸟要早起 2013-11-04 12:43发表 [回复]
- 回复jackhes02:你是在64位系统上跑的吧?
处理办法就是下载src在64位机器上面编译一下。因为直接下载的是适用于32机器的。blog上面有讲到的
- 9楼 外星茹敬雨拦不住 2013-11-03 21:10发表 [回复]
- 您好,我是hadoop的新手。
我想问一下,既然hadoop2.2 已经发布,还有没有必要先学习下hadoop1.2.他们两者之间差距大吗?
网上关于2.2的资料很少,大部分都是1.2的。
希望您能给个建议,谢谢啦~
- Re: 我是菜鸟要早起 2013-11-03 21:47发表 [回复]
-
您好,由于2.2是10月份刚刚发布的,所以网上相关资料都非常少,甚至2.0版本以后都很难找到比较详细的中午资料,所以最权威的还是查看Apache的英文资料,我配置过程中也主要参考的那些。至于您提到的是否需要学习一下以往版本进行对比,这个取决您学习的目的,如果只是简单的想部署集群,并且跑一些程序,或者仅仅使用hdfs进行存储,那么我觉得就不是很有必要了。如果您要学习mapreduce编程,或者想研究2.0以后hadoop的各种改进,那么有必要了解一下以往版本。
- Re: 外星茹敬雨拦不住 2013-11-04 09:51发表 [回复]
- 回复licongcong_0224:非常感谢您的回复,我决定还是先学习下hadoop1.2,作为新手,直接看英文有些困难。以后还望多多赐教,再次感谢~
- Re: 我是菜鸟要早起 2013-11-04 12:41发表 [回复]
- 回复rjy1989:赐教不敢当,欢迎互相学习交流
- 8楼 jackhes02 2013-11-03 17:50发表 [回复]
- --启动yarn始终无法启动,请帮忙看看。我QQ:17032053;希望能向你请教,谢谢。
[zzhadoop@vm2 hadoop]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/zzhadoop/hadoop-2.2.0/logs/yarn-zzhadoop-resourcemanager-vm2.out
sst-db: starting nodemanager, logging to /home/zzhadoop/hadoop-2.2.0/logs/yarn-zzhadoop-nodemanager-sst-db.out
vm1: starting nodemanager, logging to /home/zzhadoop/hadoop-2.2.0/logs/yarn-zzhadoop-nodemanager-vm1.out
[zzhadoop@vm2 hadoop]$
[zzhadoop@vm2 hadoop]$ jps
2352 NameNode
2699 SecondaryNameNode
3111 Jps
[zzhadoop@vm2 hadoop]$ cat /home/zzhadoop/hadoop-2.2.0/logs/yarn-zzhadoop-resourcemanager-vm2.out
ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 1031728
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65536
- Re: 我是菜鸟要早起 2013-11-03 21:07发表 [回复]
- 回复jackhes02:你查看一下yarn-zzhadoop-resourcemanager-vm2.log这个里面的信息吧,看看RM没有启动的原因在哪里?
- Re: jackhes02 2013-11-04 09:57发表 [回复]
- 回复licongcong_0224:问题已解决,报错如下:
2013-11-04 09:42:43,405 INFO org.apache.hadoop.service.AbstractService: Service org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService failed in state INITED; cause: java.lang.IllegalArgumentException: Does not contain a valid host:port authority: vm2:8031 (configuration property 'yarn.resourcemanager.resource-tracker.address')
java.lang.IllegalArgumentException: Does not contain a valid host:port authority: vm2:8031 (configuration property 'yarn.resourcemanager.resource-tracker.address')
---原因是在填写配置文件yarn-site.xml 时主机名前多了一个空格。
- Re: 我是菜鸟要早起 2013-11-04 12:41发表 [回复]
- 回复jackhes02:哈哈,,有有时候手误还真的会带来一些很纠结的问题。恭喜!!谢谢问题反馈!
- 7楼 蜗蜗牛快跑 2013-11-03 11:33发表 [回复]
- 您好,今天照您的教程做了一遍,我用的两台 Ubuntu。001按照配置启动hdfs后,有这几个进程:
10029 DataNode
10491 Jps
9696 NameNode
10361 SecondaryNameNode
但是002的datanode没启动。。。那边完全没反应,您看问题可能出在哪?
hadoop是如何让002的datanode启动的?这个原理我就没想明白。难道是通过slaves文件里面的配置么?
- Re: 我是菜鸟要早起 2013-11-03 14:45发表 [回复]
-
1)001上面有datanode进程?你是不是把001也写进到slaves中了
2)002中的datanode进程是通过slaves中的配置检查到,从而启动的。
3)你检查一下你的/etc/hosts中配置是否正确
- Re: 蜗蜗牛快跑 2013-11-03 19:31发表 [回复]
- 回复licongcong_0224:您好,我是slaves添加了namenode的主机名才导致错误的。后面改了下,start-dfs.sh可以成功运行,但是start-yarn.sh 命令却无法启动相关进程,log报错: Error starting ResourceManager
java.lang.IllegalArgumentException: Does not contain a valid host:port authority: 。。。。。。
网上查倒是有相关先例,有说主机名不能包含大写字母(我的有包含)或者下划线,也有说配置文件路径不对。您有空帮我分析分析,感激不尽
- Re: 我是菜鸟要早起 2013-11-03 21:01发表 [回复]
- 回复superbinbin1:你查一下位于namenode这台机器上面的log,关于RM无法启动的原因是什么?既然namenode进程都启动了,个人觉得应该不是hostname命名方式的问题了吧?
- 6楼 buptwuguohua 2013-11-01 16:44发表 [回复]
- 你好,我按照你的配置,最后发现datanode无法启动,找了很久没找到原因,我的qq是331836971,希望能帮忙解决一下。
- Re: 我是菜鸟要早起 2013-11-01 20:05发表 [回复]
- 回复buptwuguohua:你可以查看一下datanode上面的log信息,datanode无法启动的原因八成是你多次format namenode造成的。log中有详细原因,解放方法也很简单
- Re: buptwuguohua 2013-11-01 23:42发表 [回复]
- 回复licongcong_0224:问题已经解决,主要是两个问题:
1. clusterID不一致,namenode的cid和datanode的cid不一致,导致的原因是对namenode进行format的之后,datanode不会进行format,所以datanode里面的cid还是和format之前namenode的cid一样,解决办法是删除datanode里面的dfs.datanode.data.dir目录和tmp目录,然后再启动start-dfs.sh
2.即使删除iptables之后,仍然报Datanode denied communication with namenode: DatanodeRegistration错误,参考文章,可以知道需要把集群里面每个houst对应的ip写入/etc/hosts文件就能解决问题。
- Re: 我是菜鸟要早起 2013-11-02 14:15发表 [回复]
- 回复buptwuguohua:昨晚在问题二上面纠结了那么久,呵呵~~另外,提醒大家,关闭所有机器上面的防火墙!!
- 5楼 dallar 2013-11-01 16:00发表 [回复]
- 您好,我也是hadoop新手,测试过程中发现问题,希望能交流一下。QQ:332890886
- Re: 我是菜鸟要早起 2013-11-01 20:06发表 [回复]
- 回复dallar:请问是什么问题呢?
- 4楼 唉唉唉 2013-10-31 11:32发表 [回复]
- master和所有的slaves的hadoop安装路径要一致,而且所有的配置文件<name>和<value>节点处不要有空格,否则会报错!
- Re: 我是菜鸟要早起 2013-10-31 12:35发表 [回复]
- 回复yangzhp1_1:谢谢反馈!
- 3楼 水往低处流 2013-10-30 14:46发表 [回复]
- 我的qq:605425512,方便加一下吗?有点问题请教一下
- Re: 我是菜鸟要早起 2013-10-30 15:50发表 [回复]
- 回复worklxh:已加
- 2楼 唉唉唉 2013-10-30 14:34发表 [回复]
- 你好,我有些问题想请教你!
- Re: 我是菜鸟要早起 2013-10-30 15:50发表 [回复]
- 回复yangzhp1_1:已加
- 1楼 唉唉唉 2013-10-30 11:16发表 [回复]
- 问一下后续问题 你是怎么在eclipse中开发的??
- Re: 我是菜鸟要早起 2013-10-30 14:14发表 [回复]
- 回复yangzhp1_1:目前我个人还没有涉及到并行程序的具体开发工作,只是在hive下通过编写脚本对hdfs上面的数据进行简单处理。
更多推荐
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程











发布评论