 题目(基于Matplotlib)"/>
题目(基于Matplotlib)"/>
可视化案例练习题目(基于Matplotlib)
前提:要不是期末考试,我都以为我是学软件工程的,忘了自己是大数据专业的娃娃 ):
没办法,我试图用几天的时间学会数据处理,看在我这么兢兢业业的分儿上,锦鲤附体,考神保佑我过吧!!!
这些代码都是在jupyter notebook上面写的,最后转成md格式
首先,来个万能开头:
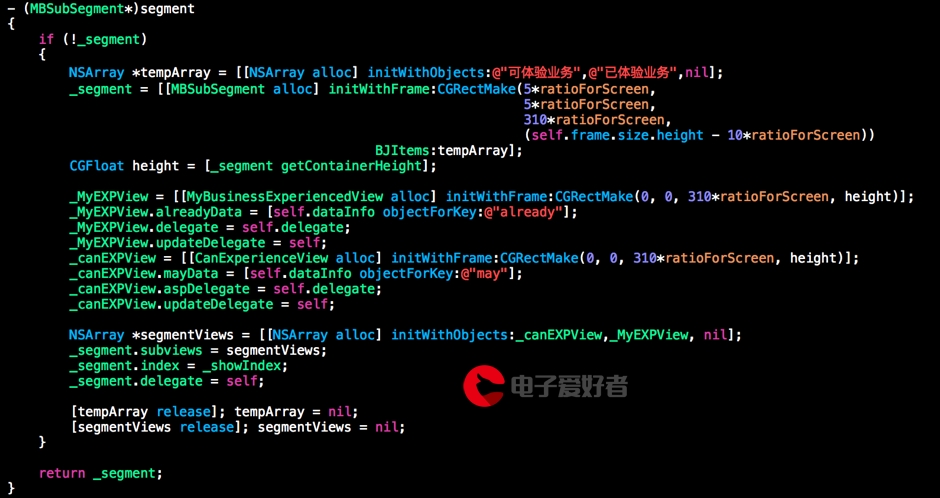
%matplotlib inline #基于jupyter notebook
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd练习1:航班乘客变化分析
data = pd.read_csv("flights.csv")
data.head()
# 年份,月份,乘客数1. 分析年度乘客总量变化情况
2. 分析乘客在一年中各月份的分布
代码如下:
ex11 = data.groupby('year').sum()
ex12 = data.groupby('month').sum()
plt.figure(figsize=(30,10),dpi=80)
plt.subplot(1,2,1)
plt.plot(ex11['passengers'])
plt.title('The number of paszengera in each year')
plt.xlabel('year')
plt.ylabel('number')
plt.xticks(ex11.index)plt.subplot(1,2,2)
x = [i+1 for i in range(len(ex12['passengers']))]
plt.bar(x,ex12['passengers'].values)
plt.title('The number of passengers in each month')
plt.xlabel('month')
plt.ylabel('number')
plt.xticks(x)
plt.show()图1-1 图 1-2
练习2:鸢尾花花型尺寸分析
- 萼片(sepal)和花瓣(petal)的大小关系
- 不同种类(species)鸢尾花萼片和花瓣的大小关系
- 不同种类鸢尾花萼片和花瓣大小的分布情况
#data = sns.load_dataset("iris")
data = pd.read_csv("iris.csv")
data.head()
# 萼片长度,萼片宽度,花瓣长度,花瓣宽度,种类# 萼片(sepal)和花瓣(petal)的大小关系(散点图)
def scatterplot1(x,y,n, x_data, y_data, x_label, y_label, title): plt.subplot(x,y,n) #plt.figure(figsize=(10,10)) plt.scatter(x_data, y_data, s=10, color = '#539caf', alpha=0.75) plt.title(title) plt.xlabel(x_label) plt.ylabel(y_label) plt.figure(figsize=(10,10))
scatterplot1(2,2,1, data['sepal_length'].values, data['petal_length'].values, 's_l', 'p_l', 's_l VS. p_l')
scatterplot1(2,2,2, data['sepal_length'].values, data['petal_width'].values, 's_l', 'p_w', 's_l VS. p_w')
scatterplot1(2,2,3, data['sepal_width'].values, data['petal_length'].values, 's_w', 'p_l', 's_w VS. p_l')
scatterplot1(2,2,4, data['sepal_width'].values, data['petal_width'].values, 's_w', 'p_w', 's_w VS. p_w')
# 萼片(sepal)和花瓣(petal)的大小关系(散点图)# 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
def scatterplot2(x,y,n,data, xlabel, ylabel, x_label, y_label, title): plt.subplot(x,y,n) #plt.figure(figsize=(10,10)) data_s = data[data.species == 'setosa'] data_ver = data[data.species == 'versicolor'] data_vir = data[data.species == 'virginica'] # 蓝色是setosa,红色是versicolor,黑色的是virginicaplt.scatter(data_s[xlabel], data_s[ylabel], s=10, color = '#539caf', alpha=0.75) plt.scatter(data_ver[xlabel], data_ver[ylabel], s=10, color = 'red', alpha=0.75) plt.scatter(data_vir[xlabel], data_vir[ylabel], s=10, color = 'black', alpha=0.75) plt.title(title) plt.xlabel(x_label) plt.ylabel(y_label) plt.figure(figsize=(12,12))
scatterplot2(2,2,1,data, 'sepal_length', 'petal_length', 's_l', 'p_l', 's_l VS. p_l')
scatterplot2(2,2,2,data, 'sepal_length', 'petal_width', 's_l', 'p_w', 's_l VS. p_w')
scatterplot2(2,2,3,data, 'sepal_width', 'petal_length', 's_w', 'p_l', 's_w VS. p_l')
scatterplot2(2,2,4,data, 'sepal_width', 'petal_width', 's_w', 'p_w', 's_w VS. p_w')
# 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)更多推荐
可视化案例练习题目(基于Matplotlib)











发布评论