 序列的声道拆分与合并"/>
序列的声道拆分与合并"/>
语音处理:Python实现Wav序列的声道拆分与合并
语音处理:Python实现Wav序列的声道拆分与合并
- 背景
- 实现思路
- Python代码
- 相关资料
背景
项目中有时需要将多声道拆分成单声道,再将单声道进行分别处理,然后再合并为多声道。为提升批量处理音频序列的效率,写了以下Python脚本,供参考。
实现思路
这里以输入序列为双声道的wav格式文件为例。
编码思路
- 单文件处理逻辑
- 多声道拆分为单声道
- 读取单文件序列,获取到分离的声道参数信息和解交织的PCM数据
- 按一定命名方式,对文件名进行修改适配
ch0/ch1/ch.. - 生成单声道文件,分别写入相应参数和数据
- 单声道合并为多声道
- 按指定命名方式,读取相应单声道文件
- 按原始声道数,将PCM数据进行组合
- 生成多声道文件,分别写入相应参数和数据
- 自验证
- 输入双声道序列
- 调用多声道拆分函数
- 调用单声道合并函数
- 对比合并后序列与拆分前原始序列是否比特一致
- 多声道拆分为单声道
- 批处理调度逻辑
- 对目录内所有多声道文件获取文件绝对路径
- 循环调用上述单文件处理逻辑
其中,利用到了Python自带模块scipy.io里的wavfile包来进行wav文件读写处理。
Python代码
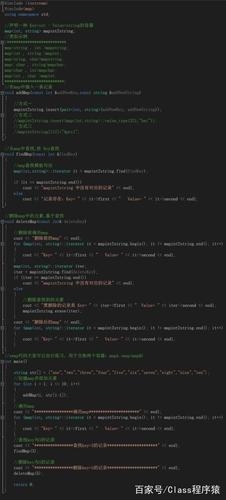
import sys
import os
import numpy as np
from scipy.io import wavfile'''' 辅助处理函数 '''''# 获取当前目录下所有文件对应的绝对路径,dir_in下面不能包含子目录
def get_dir_files_path(dir_in):files_path = []for (dirpath, dirnames, filenames) in os.walk(dir_in):for filename in filenames:files_path += [os.path.join(dirpath, filename)]files_path.sort()return files_path'''' 声道处理函数 '''''# 读取wav输入数据,并解交织为[声道数,时序样点]
def read_wav_data(file_in):samplerate, data = wavfile.read(file_in) # data: [time, ch]data = np.array(data)data = data.T # data: [ch, time]return samplerate, data# 拆分多声道wav为单声道wav
def split_stereo_to_mono(input_path, output_path):# default stereosamplerate, data = read_wav_data(input_path)ch_num = 0for ch in data:mono = []mono.append(ch)file_name = input_path.split('\\')[-1]file_name = file_name.split('.')[0]#outfile_name = file_name + '_mono_ch{0}_170kbps.wav'.format(ch_num)outfile_name = file_name + '_mono_ch{0}.wav'.format(ch_num)out_path_file = os.path.join(output_path, outfile_name)mono_data = np.array(mono).Twavfile.write(out_path_file, samplerate, mono_data)ch_num += 1# 合并单声道wav为多声道wav
def merge_mono_to_stereo(input_path, ref_path, output_path):file_name = ref_path.split('\\')[-1]file_name = file_name.split('.')[0]ch_num = 2stereo_data = []samplerate = -1for i in range(ch_num):file_in_name = file_name + '_mono_ch{0}_{1}kbps.wav'.format(i, CONST_TEST_BR)file_in_path = os.path.join(input_path, file_in_name)samplerate, data = read_wav_data(file_in_path)stereo_data.append(data)outfile_name = file_name + '_{0}kbps_merge.wav'.format(CONST_TEST_BR * ch_num)out_path_file = os.path.join(output_path, outfile_name)stereo_data = np.array(stereo_data).Twavfile.write(out_path_file, samplerate, stereo_data)# 验证拆分、合并前后数据是否正常
def seq_closed_process():input_path = r'E:\seq_test\tmp\test.wav'output_path = r'E:\seq_test\tmp'split_stereo_to_mono(input_path, output_path)merge_mono_to_stereo(input_path, output_path)return# 序列前处理,多声道拆分
def seq_pre_process(dir_in, dir_out):input_files_path = get_dir_files_path(dir_in)for input_path in input_files_path:split_stereo_to_mono(input_path, dir_out)return# 序列后处理,单声道合并
def seq_post_process(dir_in, dir_ref, dir_out):input_files_path = get_dir_files_path(dir_ref)for input_path in input_files_path:merge_mono_to_stereo(dir_in, input_path, dir_out)return相关资料
- 语音处理:Python实现音频文件声道分离批量处理,link
- Python实践:文件读写功能之txt文本,link
更多推荐
语音处理:Python实现Wav序列的声道拆分与合并











发布评论