 pandas groupby() 的使用"/>
pandas groupby() 的使用"/>
pandas groupby() 的使用
在数据分析中,经常会用到分组,可用函数 pandas 中的groupby()。
groupby()主要的分组统计方向:
1、分组汇总
2、分组描述性统计分析
3、分组计算均值等统计量
4、分组去重
5、分组排序取样本
6、分组汇总,然后再分组计算
Date Latitude Longitude Depth Type
01/02/1965 19.246 145.616 131.6 Earthquake
01/04/1965 1.863 127.352 80.0 Earthquake
01/05/1965 -20.579 -173.972 20.0 Earthquake
01/08/1965 -59.076 -23.557 15.0 Earthquake
01/09/1965 11.938 126.427 15.0 Earthquake
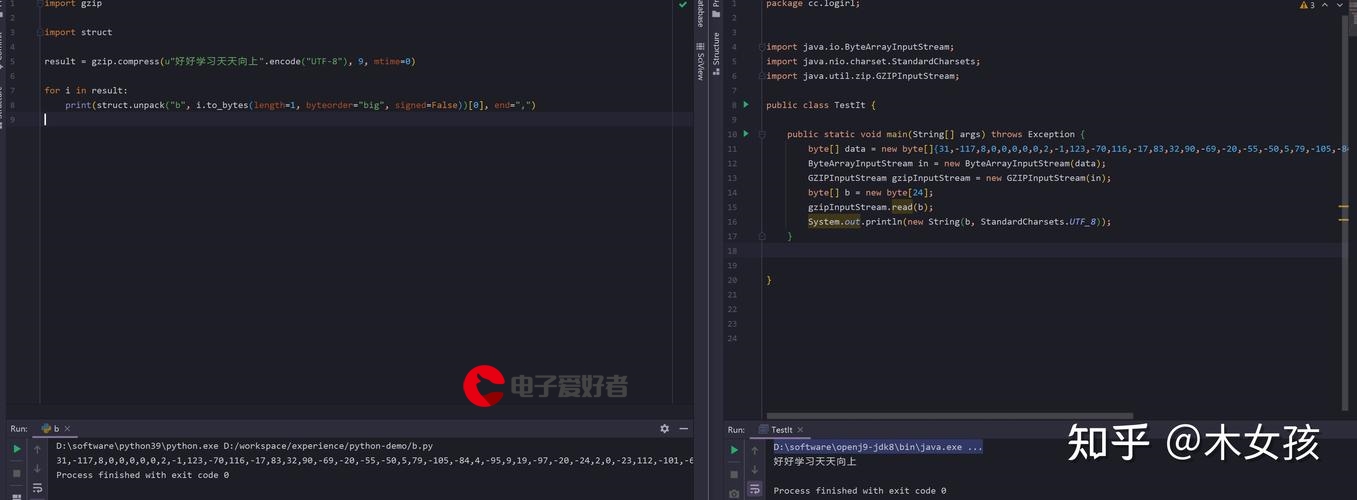
#1、分组统计组内个数
df.groupby(['date','Type']).size()#2、分组统计计算‘Depth’的基本数据分布
df.groupby(['date','type'])['Depth'].describe()#3、分组统计计算‘Latitude’的均值
df.groupby(['date','type']).agg({'Latitude':'mean'})#分组统计计算两列数据的均值
df.groupby(['date','type']).agg(la_mean = ('Latitude','mean'),lo_mean = ('Longitude','mean'),la_range = ('depth',lambda x:x.max() - x.min()))#4、分组然后对每组去重,然后汇总去重后的个数
df.groupby('date').apply(lambda x: x.drop_duplicates('Type')['Type'].count())#5、分组,然后按照‘Latitude’降序,并取出每组的前3个样本。
df.groupby(['date']).apply(lambda x: x.sort_values('Latitude',ascending = False).head(3))#6、分组,然后汇总计算两列数据,再进行分组,取出每一组‘la_sum'的最大值
df.groupby(['date','type']).agg(la_sum = ('Latitude','sum'),lo_sum = ('Longitude','sum')).groupby(['date']).apply(lambda x:x.sort_values('la_sum ',ascending = False).head(1))#分组,然后按照type排序,再分组,取出前10汇总和后10汇总,然后再计算两者的比率
df.groupby('date').apply(lambda x:x.sort_values('type')).reset_index(drop = True).groupby('date').agg(tail10 = ('depth',lambda x:x.head(10).sum()),top10 = ('depth',lambda x:x.tail(10).sum())).apply(lambda x:x['top10']/x['tail10'],axis = 1)
groupby()结合agg()和apply(),可以解决很多复杂的分组计算问题。
更多推荐
pandas groupby() 的使用











发布评论