 数据集"/>
数据集"/>
HWDB1.1数据集
❤️【专栏:数据集整理】❤️ 之【有效拒绝假数据】
👋 Follow me 👋,一起 Get 更多有趣 AI、冲冲冲 🚀 🚀
❤️ 如果文章对你有帮助、欢迎一键三连
我这里对其代码做分析和使用说明:
这里是原作者代码链接,感谢原作者PeppaPeppaPeppa
文章目录
- 📔 .gnt 转换 .png 教程如下
- 📕 gnt2png.py 文件代码
- 📗 HWDB1.1数据集 .gnt格式数据快速获取途径如下
📔 .gnt 转换 .png 教程如下
项目目录结构如下:
- 请点击这个链接 查看 ——alz 文件解压 方法 教程,If you need…
- 或者 浏览最下方 HWDB1.1数据集 .gnt格式数据快速获取途径,后台回复,即可直接获取 gnt 文件
运行命令:
python gnt2png.py
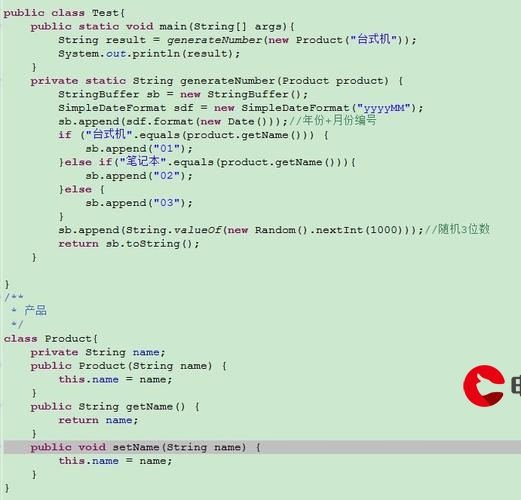
📕 gnt2png.py 文件代码
只需替换 train_data_dir 和 test_data_dir 的路径即可运行
import os
import numpy as np
import struct
from PIL import Image
# data文件夹存放转换后的.png文件
data_dir = 'data'
# 路径为存放数据集解压后的.gnt文件
train_data_dir = os.path.join('', 'wordDatas/trn_gnt')
test_data_dir = os.path.join('', 'wordDatas/tst_gnt')def read_from_gnt_dir(gnt_dir=train_data_dir):def one_file(f):header_size = 10while True:header = np.fromfile(f, dtype='uint8', count=header_size)if not header.size: breaksample_size = header[0] + (header[1] << 8) + (header[2] << 16) + (header[3] << 24)tagcode = header[5] + (header[4] << 8)width = header[6] + (header[7] << 8)height = header[8] + (header[9] << 8)if header_size + width * height != sample_size:breakimage = np.fromfile(f, dtype='uint8', count=width * height).reshape((height, width))yield image, tagcodefor file_name in os.listdir(gnt_dir):if file_name.endswith('.gnt'):file_path = os.path.join(gnt_dir, file_name)with open(file_path, 'rb') as f:for image, tagcode in one_file(f):yield image, tagcodechar_set = set()
for _, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')char_set.add(tagcode_unicode)
char_list = list(char_set)
char_dict = dict(zip(sorted(char_list), range(len(char_list))))
print(len(char_dict))
print("char_dict=", char_dict)import picklef = open('char_dict', 'wb')
pickle.dump(char_dict, f)
f.close()
train_counter = 0
test_counter = 0
for image, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')im = Image.fromarray(image)
# 路径为data文件夹下的子文件夹,train为存放训练集.png的文件夹dir_name = 'data/train/' + '%0.5d' % char_dict[tagcode_unicode]print(dir_name)if not os.path.exists(dir_name):os.mkdir(dir_name)im.convert('RGB').save(dir_name + '/' + str(train_counter) + '.png')print("train_counter=", train_counter)train_counter += 1
print('Train transformation finished ...')
for image, tagcode in read_from_gnt_dir(gnt_dir=test_data_dir):tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')im = Image.fromarray(image)
# 路径为data文件夹下的子文件夹,test为存放测试集.png的文件夹dir_name = 'data/test/' + '%0.5d' % char_dict[tagcode_unicode]if not os.path.exists(dir_name):os.mkdir(dir_name)im.convert('RGB').save(dir_name + '/' + str(test_counter) + '.png')print("test_counter=", test_counter)test_counter += 1
print('Test transformation finished ...')📗 HWDB1.1数据集 .gnt格式数据快速获取途径如下
- 我下载 HWDB1.1数据之后,把里面的 alz 格式的训练数据 压缩包,进行解压之后得到 内部 .gnt 文件;
搜索关注本博客同名公号,公号后台,回复
【
20201101】 获取本博文中的 HWDB1.1数据集解压后的 gnt 文件云盘下载链接,下载之后,便可以直接使用上面代码 把 .gnt 转换 .png格式:
20201101
Game Over ,感谢三连
更多推荐
HWDB1.1数据集











发布评论