Jér*_*ard 5
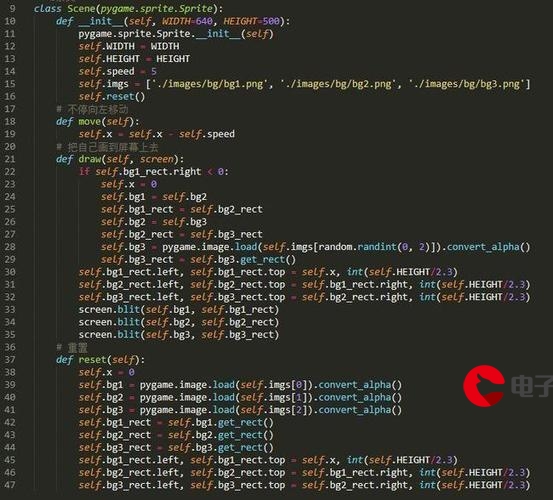
一种有效的解决方案是首先使用对输入值进行排序index = np.argsort()。然后,您可以使用 生成排序数组,然后如果快速连续数组上的对数较少,则在准线性时间内arr[index]迭代接近的值。如果对的数量很大,那么由于生成的对数是二次的,所以复杂度是二次的。由此产生的复杂性是:其中是输入数组的大小,是产生的对数。O(n log n + m)nm
要找到彼此接近的值,一种有效的方法是使用Numba迭代值。事实上,虽然在 Numpy 中可能是可行的,但由于要比较的值的数量可变,它可能效率不高。这是一个实现:
import numba as nb
@nb.njit('int32[:,::1](float64[::1], float64)')
def findCloseValues(arr, tol):
res = []
for i in range(arr.size):
val = arr[i]
# Iterate over the close numbers (only once)
for j in range(i+1, arr.size):
# Sadly neither np.isclose or np.abs are implemented in Numba so far
if max(val, arr[j]) - min(val, arr[j]) >= tol:
break
res.append((i, j))
if len(res) == 0: # No pairs: we need to help Numpy to know the shape
return np.empty((0, 2), dtype=np.int32)
return np.array(res, dtype=np.int32)
最后,需要更新索引以引用未排序数组中的索引而不是排序数组。您可以使用index[result].
这是生成的代码:
index = arr.argsort()
result = findCloseValues(arr[index], 1.0)
print(index[result])
这是结果(顺序与问题中的不同,但您可以根据需要对其进行排序):
array([[9, 3],
[9, 7],
[3, 7],
[1, 5],
[4, 2]])
提高算法的复杂度
如果您需要更快的算法,那么您可以使用另一种输出格式:您可以为每个输入值提供接近目标输入值的最小值/最大值范围。要查找范围,您可以在已排序的数组上使用二分查找(参见np.searchsorted:)。生成的算法在O(n log n). 但是,您无法获取未排序数组中的索引,因为该范围是不连续的。
基准
以下是在我的机器上随机输入 1000 个项目和容差为 1.0 的性能结果:
array([[9, 3],
[9, 7],
[3, 7],
[1, 5],
[4, 2]])
更多推荐
组中,最快,方法,Numpy






发布评论